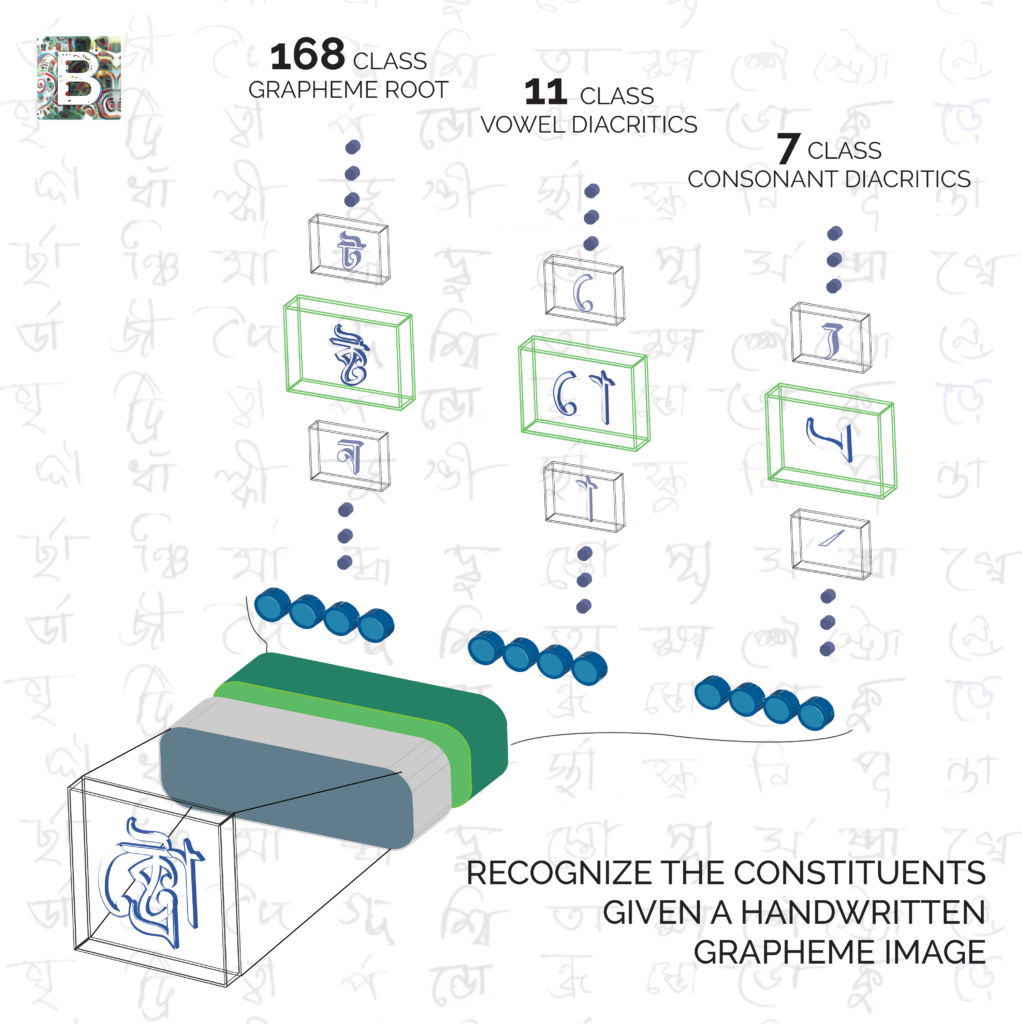
I took part in a Kaggle challenge presented by Bengali AI. The goal of this challenge is to build a machine learning model to identify images of handwritten Bengali graphemes, thus improving the state of the art for Bengali optical character recognition. Each grapheme has three parts: a grapheme root, a vowel diacritic, and a consonant diacritic. The grapheme root is one of 168 classes, the vowel diacritic is one of 11 classes, and the consonant diacritic is one of 7 classes. The training set provided by Bengali.ai includes 200,840 images. Kaggle ranked the entries by computing the fraction of all of the predictions (three per image) over a test set of about 200,000 images. In my opinion, it would be a better metric to compute the fraction based on the graphemes as a whole, that is, where all three components of an image must be correct to count as a correct answer. Optical character recognition of an abugida script such as Bengali should recognize the entire grapheme, not just the parts. The accuracy of the contest entries would be considerably lower if all three parts were considered for each grapheme.
I used several approaches of convolutional neural networks. I started with transfer learning with a DenseNet121 model followed by two dense layers. The final layer was split into three components for each of the three grapheme parts, such that the model output predictions in the form of a list of length 3. This gave me an accuracy of 93.7%. Then, I tried a similarly constructed MobileNet model. This gave me an accuracy of 94.4%. Finally, I tried an ensemble of both models, i.e. using an average of the probabilities from the predictions of both models to make a final prediction. This gave me an accuracy of 95.3%.
I was late to this contest, so I was not a contender for the prize. The prize had already been awarded, but I chose to do the challenge as a learning experience to improve my skills.
I built my models using Keras, and included a few pieces of code forked from a public kernel on Kaggle for image resizing. I used data augmentation with the Keras ImageDataGenerator class, including random rotations, horizontal shifts, and zoom.
As would be expected, the grapheme root was the most difficult part to predict because it included 168 classes. The classes were highly imbalanced, with some of the majority classes over 100 times more frequent than the minority classes. Class balancing weights might improve the model. I will also try implementing the new AdamW optimizer. This is similar to the beloved Adam optimizer, but with a decaying weight attached to the L2 component of the optimization algorithm. I also plan to try one or more additional models as standalone models, and as parts of an ensemble.