I did another Kaggle challenge in March. This was for a contest from Severstal Steel for detecting manufacturing defects in images of steel. There was a massive $100,000 collection of prizes. I entered the contest late and had no expectations of winning. By the time I had a testable model together the contest was over, but I was going for education, and not expecting a prize for this contest.
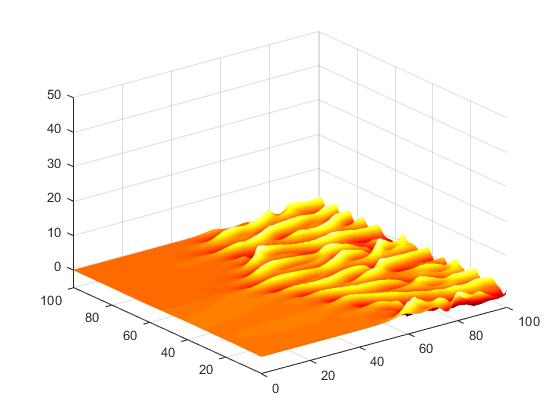
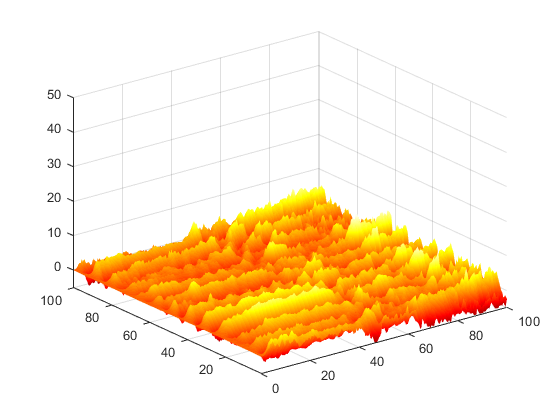
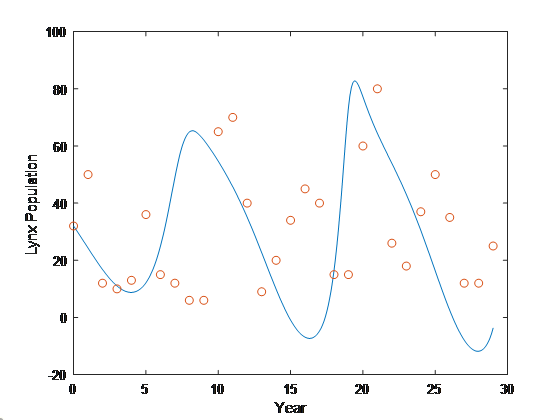
I had previously been working on a UNet model for detecting defects on aluminum workpieces, based on a data set from my previous job at Micro Encoder. This set included two types of simulated defects, one made with black spraypaint droplets, and one with graphite passed through a screen, as well as a pixel mask for the defect in each image. I was able to construct a very successful segmentation model that could detect either type of defect in an image and provide a corresponding pixel mask. I used a rather simple UNet architecture that would output two segmentation masks corresponding to each class of defect. Some sample images are below.


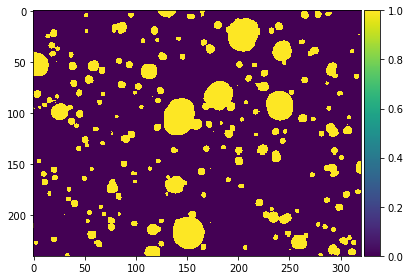

Examples of a pixel mask that my model predicted (left) and the actual pixel mask (right).
The Kaggle data set was a bit more complicated. There were four types of defects and unlike the earlier data set, some images included more than one type of defect. I used a similar approach with images downsampled by various scale factors, but my UNet model did not give very good results as measured by a Dice coefficient. I then tried using transfer learning using the Keras segmentation-models library with a ResNet34 backbone . I trained on a subset of data that included an equal number of images from each class of defect. I also added some augmented images with horizontal flips and vertical flips. When I used images downsampled by a scale factor of 2 (i.e. to 800×128), it bumped me above 0.80 for the dice coefficient. I then tried using an ensemble of models to improve accuracy. I used three UNet models with backbones including ResNet34, DenseNet121, and Inception. This gave me a dice coefficient of about 0.84. The winning submissions for the contests were around 0.90 for the dice coefficient. I hope to improve to something even closer to that.
I am now working on an improved model which uses a data pipeline with a data generator class rather than just a big numpy array, so I can avoid memory problems with large training data sets. I am also using more augmentation such as zoom and rotations. I hope to have some results soon.